一、Chunking 句子分块
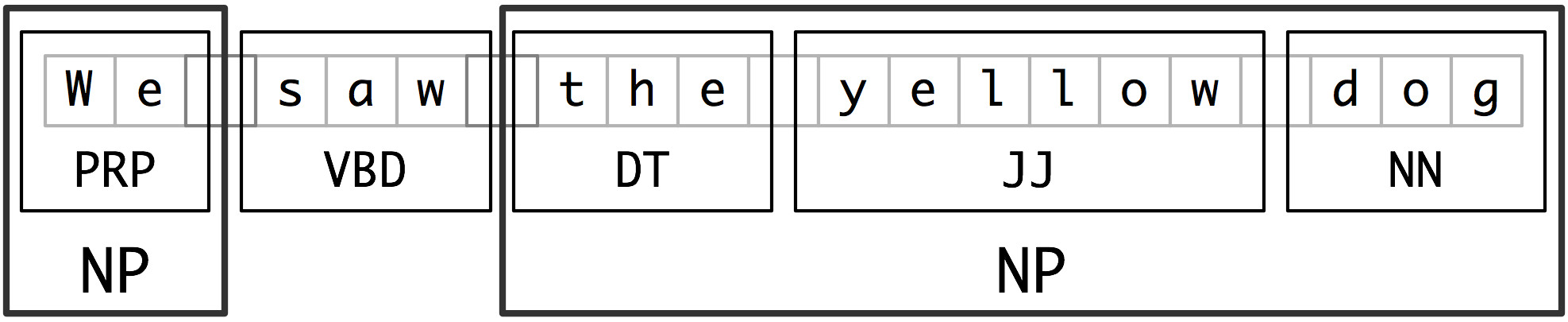
Segmentation and Labeling at both the Token and Chunk Levels
1 noun phrase chunking( NP-chunking)名词短语
import nltk
sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
grammar = "NP: {<DT>?<JJ>*<NN>}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print(result)
result.draw()
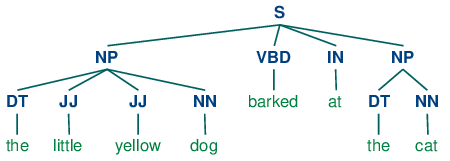
----------------------------------------------------------
如果觉得上述对句子人式标注很麻烦,可以改为以下:
import nltk
sentence="the little dog baked at the cat"
words=nltk.word_tokenize(sentence) #分词
sent_tag=nltk.pos_tag(words) #加标注
grammar = "NP: {<DT>?<JJ>*<NN>}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sent_tag)
print(result)
result.draw()
练习1:考虑下面的名词短语如何表示。
another/DT sharp/JJ dive/NN
trade/NN figures/NNS
any/DT new/JJ policy/NN measures/NNS
earlier/JJR stages/NNS
Panamanian/JJ dictator/NN Manuel/NNP Noriega/NNP二、句子结构分析
1 句子嵌套
Usain Bolt broke the 100m recordb.
The Jamaica Observer reported that Usain Bolt broke the 100m recordc.
Andre said The Jamaica Observer reported that Usain Bolt broke the 100m recordd.
I think Andre said the Jamaica Observer reported that Usain Bolt broke the 100m record
2 句子歧义
I shot an elephant in my pajamas.http://www.nltk.org/book/ch08.html
groucho_grammar = nltk.CFG.fromstring("""
S -> NP VP
PP -> P NP
NP -> Det N | Det N PP | 'I'
VP -> V NP | VP PP
Det -> 'an' | 'my'
N -> 'elephant' | 'pajamas'
V -> 'shot'
P -> 'in'
""")
sent = ['I', 'shot', 'an', 'elephant', 'in', 'my', 'pajamas']
parser = nltk.ChartParser(groucho_grammar)
for tree in parser.parse(sent):
print(tree)
3 Context Free Grammar 上下文无关文法
(1)递归下降解析器
nltk.app.rdparser()
(2)移进-归约解析器
nltk.app.srparser()

















评论 0