-----------------------------------------------------------
标注的简单运用:统计分析
1. 统计分析新闻文档中,什么类型的词用得最多
from nltk.corpus import brown
brown_news_tagged = brown.tagged_words(categories='news', tagset='universal')
tag_fd = nltk.FreqDist(tag for (word, tag) in brown_news_tagged)
tag_fd.most_common()
2. 找出最频繁的名词标记
import nltk
def findtags(tag_prefix, tagged_text):
cfd = nltk.ConditionalFreqDist((tag, word) for (word, tag) in tagged_text if tag.startswith(tag_prefix))
return dict((tag, cfd[tag].most_common(5)) for tag in cfd.conditions())
tagdict = findtags('NN', nltk.corpus.brown.tagged_words(categories='news'))
for tag in sorted(tagdict):
print(tag, tagdict[tag])
三、Information Extraction 信息抽取
--------------------------------
OrgName LocationName
Omnicom New York
DDB Needham New York
Kaplan Thaler Group New York
BBDO South Atlanta
Georgia-Pacific Atlanta
----------------------------------------
Companies that operate in Atlanta
OrgName
BBDO South
Georgia-Pacific------------------------------------------------------------------
如果信息蕴含于文本中
The fourth Wells account moving to another agency is the packaged paper-products division of Georgia-Pacific Corp., which arrived at Wells only last fall. Like Hertz and the History Channel, it is also leaving for an Omnicom-owned agency, the BBDO South unit of BBDO Worldwide. BBDO South in Atlanta, which handles corporate advertising for Georgia-Pacific, will assume additional duties for brands like Angel Soft toilet tissue and Sparkle paper towels, said Ken Haldin, a spokesman for Georgia-Pacific in Atlanta.
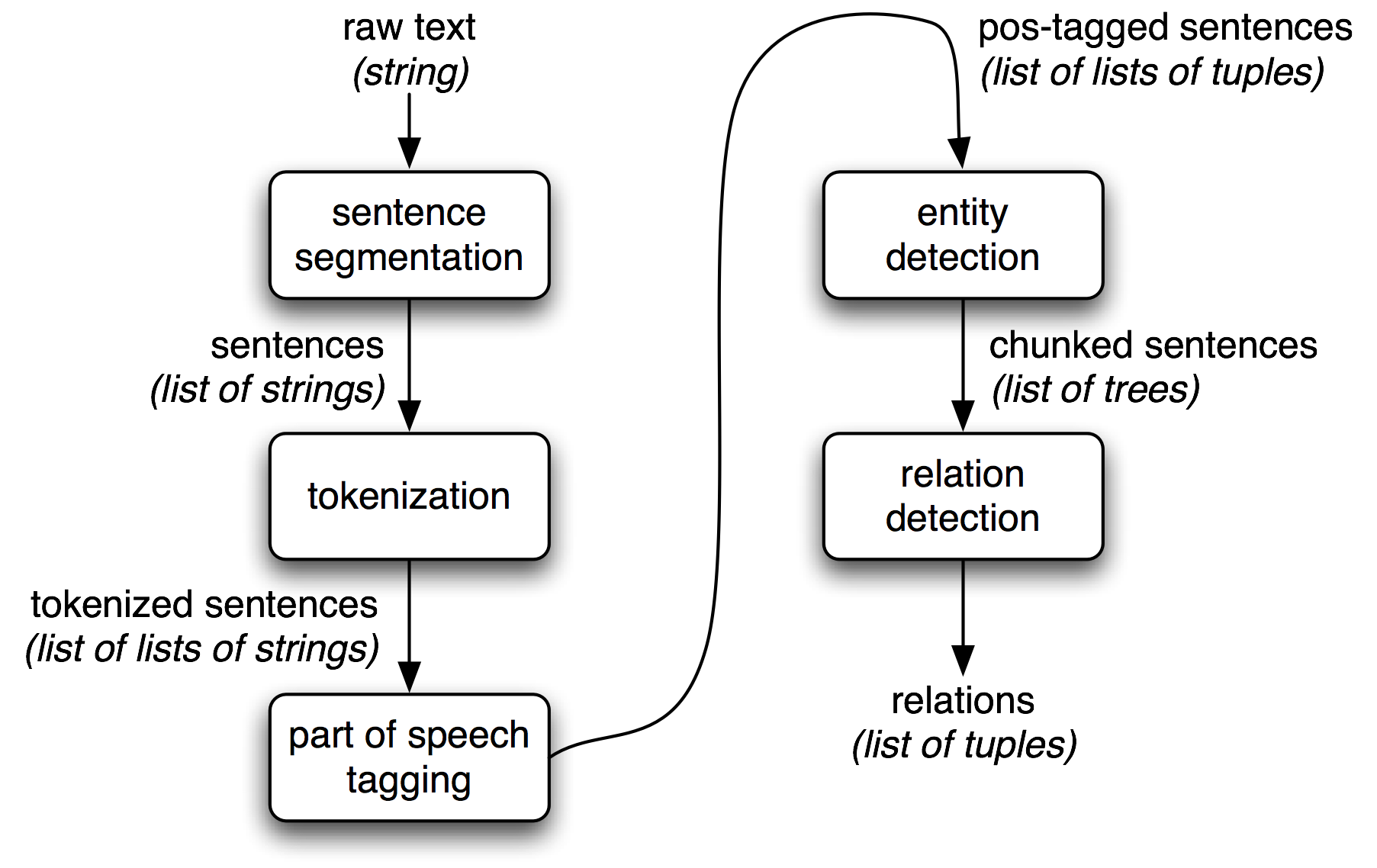
Information Extraction Architecture信息抽取过程示意图

















评论 0